Data structures are vital in computer science for efficient data organization and manipulation. Today, we will explore one of the most efficient data structures for key-value pair storage: the Hashtable.
What is a Hashtable?
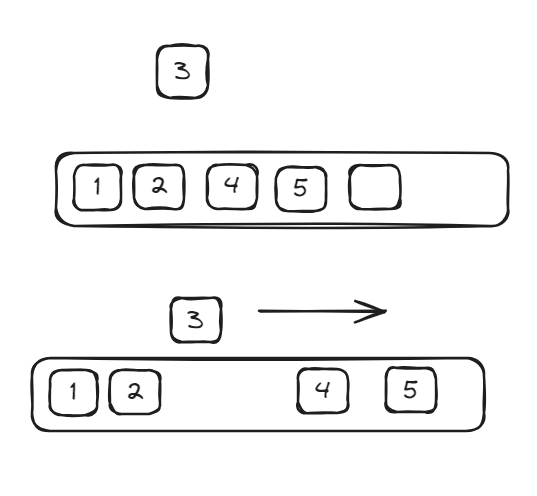
A Hashtable, also known as a hashmap, is a data structure that maps keys to values for highly efficient data retrieval. It uses a hash function to compute an index into an array of buckets or slots. Its amazing superpower is fast reading, with time complexity of O(1) when finding an element and inserting it.
Core concepts of Hashtable
- Hash Function: A function that convers a given key into an index in the hashtable. A good hash function distributes keys uniformly across the buckets.
- Buckets: Array slots where the key-value pairs are stored. Each bucket can store multiple key-value pairs in case of collision.
- Collision Handling: Techniques to handle situations where multiple keys hash to the same index. Common methods include chaining and open addressing.
Hashing with hash functions
We can image how hash function work with simple example like this:
Map letters to numbers:
- A = 1
- B = 2
- C = 3
- D = 4
- E = 5
- ABC converts to 123
- ABE converts to 125
- BCD converts to 234
The process of converting characters into numbers is called hashing. There are many other hashing functions besides this one. We can convert characters into numbers, then return the sum of them as an index to store key-value pairs.

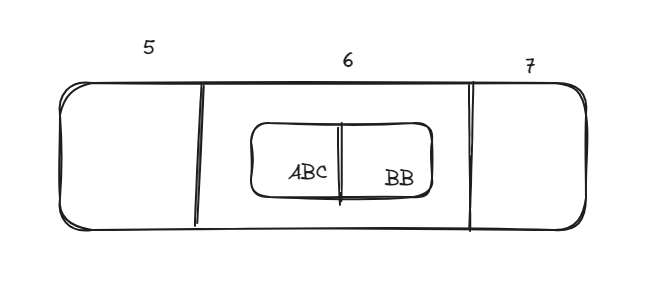
For example, we have a key-value pair: ABC – “this is the value that needs to be stored.”
- Convert ABC -> 123
- Sum is : 1 + 2 + 3 = 6
- The value is being stored in an array with index 6.
Collision Handling Techniques
So what cause Collisions, with example above if we want to store key-value: BB:”value” what will happen ? The index return is 6 that is the same as ABC key, how to deal with it
- Chaining: Each bucket contains a list (or another structure) of all key-value pairs that hash to the same index.
- Open Addressing: When a collision occurs, the algorithms searches for the next available bucket using method like linear probing, quadratic probing, or double hashing
Use Cases of Hashtable
Hashtables are widely used due to their efficiency and versatility. Some common use cases include:
- Database indexing: Fast data retrieval in databases.
- Caches: Implementing caches for quick data access.
- Counting frequencies: Counting occurrences of items (like words in a document).
Implementing a Hashtable in Python
def __init__(self, size=10):
self.size = size
self.table = [[] for _ in range(size)]
def _hash(self, key):
return hash(key) % self.size
def insert(self, key, value):
index = self._hash(key)
for kvp in self.table[index]:
if kvp[0] == key:
kvp[1] = value
return
self.table[index].append([key, value])
def lookup(self, key):
index = self._hash(key)
for kvp in self.table[index]:
if kvp[0] == key:
return kvp[1]
return None
def delete(self, key):
index = self._hash(key)
for i, kvp in enumerate(self.table[index]):
if kvp[0] == key:
del self.table[index][i]
return
Source Code: https://github.com/hongquan080799/data-structure-and-algorithms
Conclusion
Hashtables are a powerful data structure providing efficient key-value pair storage and retrieval. Their average-case time complexity of O(1) for insertion and lookup makes them invaluable in many applications, from database indexing to implementing caches. Understanding the fundamentals of hashtables, including hash functions and collision handling, is essential for optimizing data storage and access in your programs.