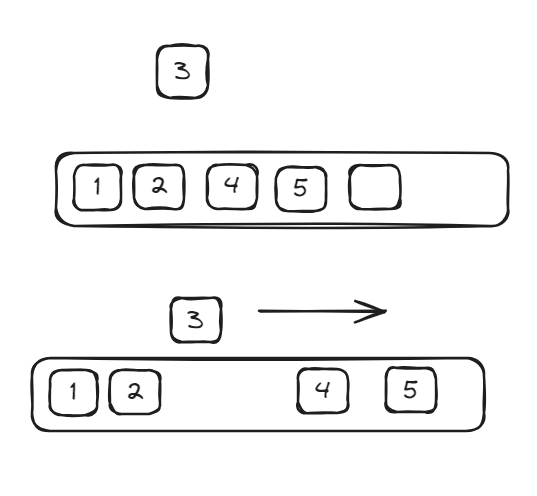
In the world of computer science, data structures are essential for organizing and storing data efficiently. Today we gonna learn about Linked list. Despite its simplicity, it forms the basic for many more complex data structures
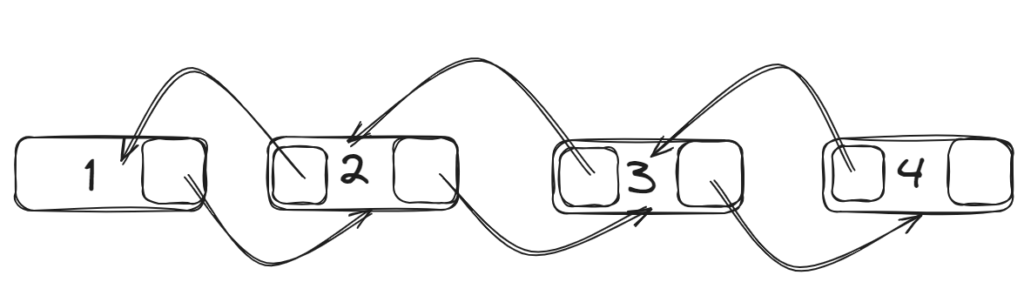
What is a Linked List ?
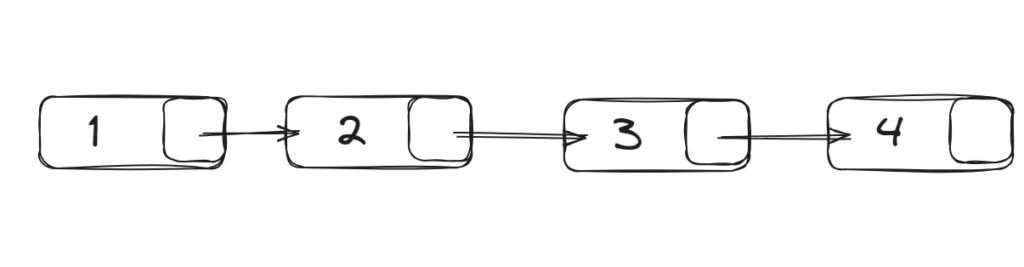
A Linked List is a linear data structure where elements, also known as nodes, are not stored at contiguous memory locations. Instead, each node contains two components:
- Data: The value stored in the node
- Pointer: Pointing to the next node in the sequence (store address of next node)
The first node called Head, and the last is called tail.
Types of Linked Lists
- Singly Linked List
- In a Singly Linked List, each node points to the next node in the sequence, and the last node points to null, allow traversal in only one direction
- Doubly Linked List
- A Doubly Linked List allows traversal in both directions. Each node contains two pointers
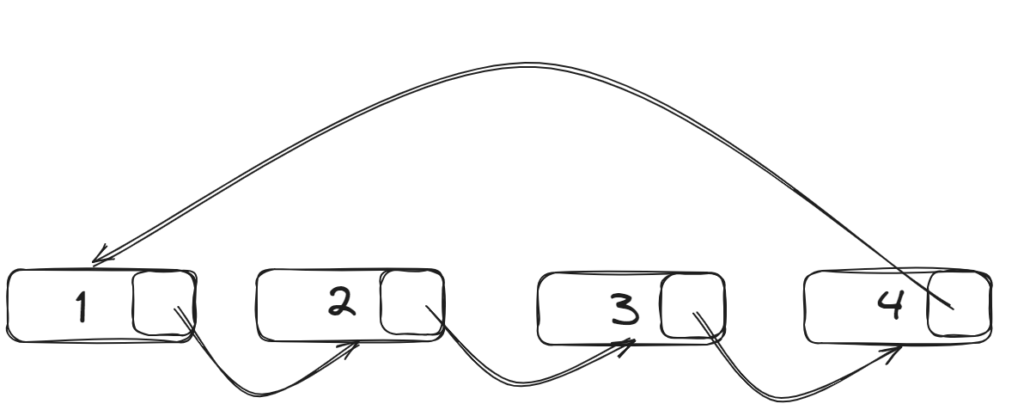
- Circular Linked List
- In a Circular Linked List
- In a Circular Linked List, the last node points back to the head instead of null, forming a circular structure. This can be implemented as either singly or doubly linked
Operations on Linked Lists
Node declaration:
class Node:
def __init__(self, data):
self.data = data
self.next = None
Insertion: Insertion can be performed at various positions in a Linked List
- At the beginning: Adjust the head to point to the new node.
- At the end: Traverse to the end and update the last node’s pointer.
- At a specific position: Traverse to the position and adjust the pointers accordingly.
def insert_at_beginning(head: Node,data):
new_node = Node(data)
new_node.next = head
head = new_node
def insert_at_end(head: Node, data):
new_node = Node(data)
if head is None:
head = new_node
return
last = head
while last.next:
last = last.next
last.next = new_node
def insert_at_position(head: Node, data, position):
if position < 0:
raise ValueError("Position must be a non-negative integer.")
new_node = Node(data)
if position == 0:
new_node.next = head
head = new_node
return
current = head
count = 0
while current is not None and count < position - 1:
current = current.next
count += 1
if current is None:
raise IndexError("Position out of bounds.")
new_node.next = current.next
current.next = new_node
Deletion: Deletion can also occur at different positions
- From the beginning: Adjust the head to point to the second node.
- From the end: Traverse to the second last node and update its pointer to null.
- From a specific position: Traverse to the node before the target and adjust pointers to bypass the target node.
def delete_from_beginning(head: Node):
if head is None:
raise IndexError("List is empty.")
head = head.next
def delete_from_end(head: Node):
if head is None:
raise IndexError("List is empty.")
if head.next is None:
head = None
return
second_last = head
while second_last.next.next:
second_last = second_last.next
second_last.next = None
def delete_from_position(head: Node, position):
if head is None:
raise IndexError("List is empty.")
if position < 0:
raise ValueError("Position must be a non-negative integer.")
if position == 0:
head = head.next
return
current = head
count = 0
while current is not None and count < position - 1:
current = current.next
count += 1
if current is None or current.next is None:
raise IndexError("Position out of bounds.")
current.next = current.next.next
Traversal: Traversal involves visiting each node in the Linked List to perform operations like searching for a value, printing elements, etc. In a singly linked list, this is done from head to tail, while in a doubly linked list, it can be done in both directions.
def search(head: Node, key):
current = head
position = 0
while current:
if current.data == key:
return position
current = current.next
position += 1
return -1
Advantages of Linked Lists
- Dynamic Size: Linked Lists can grow or shrink dynamically without reallocating or reorganizing the entire structure.
- Efficient Insertions/Deletions: Adding or removing elements is efficient, especially at the beginning or end, as it only requires pointer updates.
Disadvantages of Linked Lists
- Memory Usage: Extra memory is required for storing pointers.
- Sequential Access: Accessing elements is sequential and requires traversal from the head, making random access inefficient compared to arrays.
- Complexity: Implementing operations can be more complex than arrays, especially for beginners.
Use Cases of Linked Lists
- Implementation of other data structures: Such as stacks, queues, and graphs.
- Dynamic memory allocation: Managing free memory blocks.
- Real-time applications: Where memory usage and dynamic size changes are critical.
Source Code : https://github.com/hongquan080799/data-structure-and-algorithms
Conclusion
Linked Lists are a powerful and flexible data structure that forms the backbone of many more advanced structures and algorithms. Understanding their types, operations, and use cases is crucial for any aspiring programmer or computer scientist. While they come with certain disadvantages, their advantages in specific scenarios make them an indispensable part of your data structure toolkit.