Searching is one of the core operations in computer science. Efficient searching algorithms are crucial for retrieving data quickly and accurately from various data structures. This blog will explore different types of searching algorithms, their time complexities, and use cases.
Why Searching?
Searching allows us to find specific elements within a data structure. It is essential for various applications, including database queries, information retrieval systems, and even basic functions like looking up a contact on your phone.
Types of Searching Algorithms
Searching algorithms can be broadly categorized based on their approach and the data structure they operate on. Here some common searching algorithms”
- Linear Search
- Binary Search
- Depth-First Search (DFS)
- Breadth-First Search (BFS)
- Hashing
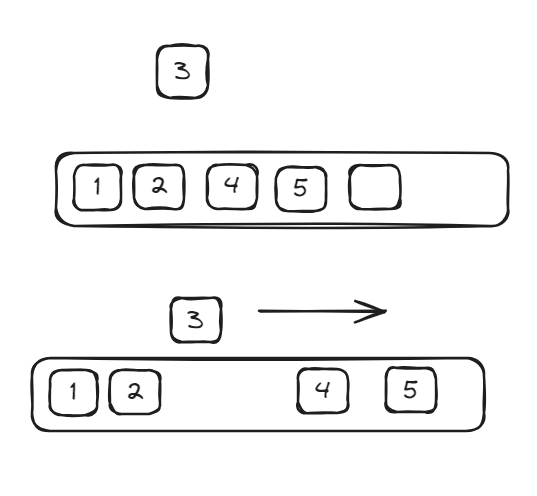
Linear Search
Description: Linear search is the simplest searching algorithm. It sequentially checks each element of the data structure until it finds the target element or reaches the end.
Time complexity: O(N), where N is the number of elements in the data structure/
Use Case: Linear search is useful for small or unsorted datatsets.
def linear_search(arr, target):
for i in range(len(arr)):
if arr[i] == target:
return i
return -1
# Example usage
array = [2, 4, 0, 1, 9]
target = 1
result = linear_search(array, target)
print(f"Element found at index: {result}")
Binary Search
Binary search is highly efficient algorithm that works on sorted arrays. It repeatedly divides the search interval in half. If the target value is less than the middle element, the search continues in the lower half; otherwise, it continues in the upper half.
Time complexity: O(LogN)
def binary_search(arr, target):
left, right = 0, len(arr) - 1
while left <= right:
mid = left + (right - left) // 2
if arr[mid] == target:
return mid
elif arr[mid] < target:
left = mid + 1
else:
right = mid - 1
return -1
# Example usage
array = [1, 2, 3, 4, 5, 6, 7, 8, 9]
target = 4
result = binary_search(array, target)
print(f"Element found at index: {result}")
Depth-First Search (DFS)
DFS is a recursive algorithm used for traversing or searching tree or graph data structures. It stats at the root (or an arbitrary node) and explores as far as possible along each branch before backtracking.
Time Complexity: O(V+E) where V is the number of vertices and E is the number of edges.
class Graph:
def __init__(self):
self.graph = {}
def add_edge(self, v, w):
if v not in self.graph:
self.graph[v] = []
self.graph[v].append(w)
def dfs_util(self, v, visited):
visited.add(v)
print(v, end=' ')
for neighbour in self.graph[v]:
if neighbour not in visited:
self.dfs_util(neighbour, visited)
def dfs(self, v):
visited = set()
self.dfs_util(v, visited)
# Example usage
g = Graph()
g.add_edge(0, 1)
g.add_edge(0, 2)
g.add_edge(1, 2)
g.add_edge(2, 0)
g.add_edge(2, 3)
g.add_edge(3, 3)
print("Following is Depth First Traversal (starting from vertex 2)")
g.dfs(2)
Breadth-First Search (BFS)
BFS is an iterative algorithm used for traversing or searching tree or graph data structures. It starts at the root (or an arbitrary node) and explores all its neighbors at the present depth level before moving on to nodes at the next depth level.
Time Complexity: O(V + E)
from collections import deque
class Graph:
def __init__(self):
self.graph = {}
def add_edge(self, v, w):
if v not in self.graph:
self.graph[v] = []
self.graph[v].append(w)
def bfs(self, s):
visited = set()
queue = deque([s])
visited.add(s)
while queue:
s = queue.popleft()
print(s, end=' ')
for neighbour in self.graph[s]:
if neighbour not in visited:
queue.append(neighbour)
visited.add(neighbour)
# Example usage
g = Graph()
g.add_edge(0, 1)
g.add_edge(0, 2)
g.add_edge(1, 2)
g.add_edge(2, 0)
g.add_edge(2, 3)
g.add_edge(3, 3)
print("Following is Breadth First Traversal (starting from vertex 2)")
g.bfs(2)
Source Code : https://github.com/hongquan080799/data-structure-and-algorithms.git
Conclusion
Searching algorithms are crucial for efficient data retrieval in various applications. Understanding the different types of searching algorithms and their use cases can help you choose the right algorithm for you specific needs. Whether you are not working with small datasets or large, complex data structures, there is a searching algorithm that fits yours requirements.